Kemarin Prof. Klieme, advisor postdoc saya, mengirimkan email yang merujuk pada sebuah artikel berjudul "Inequity and Excellence in Academic Performance: Evidence From 27 Countries." Artikel ini mencerminkan best practice dalam analisis data asesmen internasional skala besar seperti PISA, tulisnya di email. Tentu saja ini kode agar saya bukan hanya membaca, tapi juga mempelajari lebih dalam metode yang digunakan penelitian tersebut.
Kemarin Prof. Klieme, advisor postdoc saya, mengirimkan email yang merujuk pada sebuah artikel berjudul "Inequity and Excellence in Academic Performance: Evidence From 27 Countries." Artikel ini mencerminkan best practice dalam analisis data asesmen internasional skala besar seperti PISA, tulisnya di email. Tentu saja ini kode agar saya bukan hanya membaca, tapi juga mempelajari lebih dalam metode yang digunakan penelitian tersebut. Berikut beberapa hal menarik yang saya dapatkan dari pembacaan awal:
1.HIPOTESIS: HARUSKAH SELALU SEJALAN DENGAN TEORI?
Penelitian yang baik selalu merujuk pada teori yang relevan. Dalam hal ini, teori yang dirujuk berbicara mengenai perbaikan mutu pendidikan pada level sistem/negara. (Mutu di sini diartikan secara sempit sebagai rata-rata prestasi akademik siswa di sebuah negara.) Menurut teori tersebut, proses belajar-mengajar perlu disesuaikan dengan kebutuhan dan kemampuan siswa. Untuk siswa yang lebih berbakat akademik (berpikir abstrak, konseptual, dst.), sekolah perlu memberi tantangan akademik yang tinggi. Siswa yang kurang berbakat akademik sebaiknya fokus pada bidang-bidang yang lebih praktis. Dalam praktik, gagasan ini kerap diterjemahkan menjadi pemisahan jalur sekolah akademik dan vokasi.
Yang menarik, artikel tidak menyajikan penelitian yang hendak mencari bukti pendukung bagi teori tersebut. Sebaliknya, penelitian dalam artikel ini dilakukan untuk menggugurkan teori tersebut. Ini dilakukan dengan "menembak" salah satu asumsi kunci yang melandasi teori tersebut, yakni asumsi adanya trade off antara mutu/excellence (prestasi rata-rata) dan kesenjangan (variasi prestasi antar siswa). Prestasi akademik yang tinggi mau tak mau harus dicapai dengan berfokus pada siswa yang memang punya potensi akademik baik. Dengan demikian, peningkatan prestasi akademik akan meningkatkan kesenjangan alias jarak antara kelompok siswa yang berprestasi tinggi dengan kelompok di bawahnya. Asumsi inilah yang diuji, dan diharapkan (dihipotesiskan) keliru.
Jadi, riset tidak selalu harus berupaya mengkonfirmasi teori. Niat untuk menggugurkan teori itu sah-sah saja sebagai tujuan penelitian. Justru di sinilah kekhasan ilmu pengetahuan (sains). Dalam sains, teori memang harus bisa dibuktikan keliru, dan penelitian ilmiah justru perlu membuka kemungkinan terjadinya falsifikasi. Ketika ini terjadi, maka tugas selanjutkan adalah mengembangkan teori baru yang dapat menjelaskan data dan fenomena.
2. DATA SEKUNDER LEBIH RENDAH DERAJATNYA DIBANDING DATA PRIMER?
Artikel ini menganalisis data dari PISA (Program for International Student Assessment), survei tiga-tahunan yang dilakukan pada siswa kelas 9-10 di puluhan negara sejak tahun 2000. Indonesia termasuk negara yang menjadi peserta setia survei PISA. Untuk artikel ini, para peneliti menggunakan data PISA tahun 2000, 2003, 2006, 2009, dan 2012 dari 30 negara maju. Data PISA disediakan oleh OECD (penyelenggara PISA) secara daring di laman yang bisa diakses oleh siapa pun. Artinya, para penulis artikel ini menggunakan data yang dikumpulkan oleh peneliti/lembaga lain, alias data sekunder.
Apakah penggunaan data sekunder mengurangi nilai penelitian dan artikel ini? Menurut saya sih, tidak serta merta demikian. Penelitian dengan data sekunder memiliki plus dan minus, tapi demikian juga dengan penelitian data primer. Yang jelas, disertasi doktor berbagai universitas top dunia cukup banyak yang menggunakan data sekunder. Jurnal-jurnal ilmiah kelas dunia tidak alergi dengan penelitian data sekunder (artikel ini contohnya). Ini berbeda dengan praktik banyak program studi di perguruan tinggi Indonesia yang kerap mengharuskan mahasiswanya menggunakan data primer untuk riset akhir mereka.
3. METODE ANALISIS
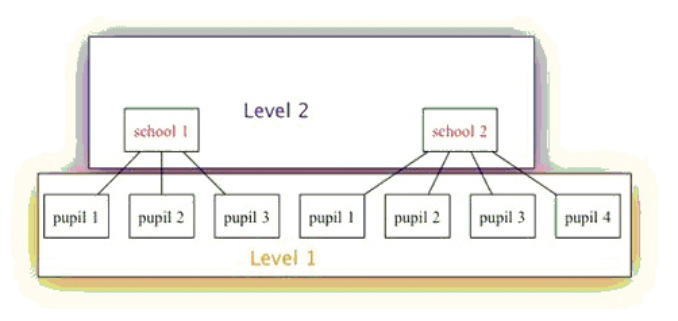
Ini bagian yang paling sulit dipahami dari artikel ini. Analisis data skala besar seperti PISA, apalagi jika melibatkan perbandingan puluhan negara dan beberapa periode waktu, menuntut statistik yang canggih. Ini sebagian saja dari metode dan teknik statistik tersebut: item-response theory untuk mendapatkan skor laten, sampling weight untuk mengkoreksi bias pengambilan sampel, pemodelan multi-jenjang (multilevel modelling) untuk data yang memang terklaster (siswa dalam sekolah, dan sekolah dalam negara), dll. Saya sendiri baru mulai belajar dan hanya menguasai sebagian kecil dari teknik yang digunakan artikel ini. Kompleksitas teknik statistik ini yang menjadi penghalang utama penggunaan data survei internasional seperti PISA. Meski bebas diakses siapa pun, tak semua orang punya keahlian yang diperlukan untuk mengolahnya.
Pada level yang lebih umum, pelajaran yang saya petik dari artikel ini adalah soal penggunaan beragam analisis untuk menjawab pertanyaan (menguji hipotesis) yang sama. Para penulis artikel ini berpandangan bahwa sebuah hipotesis perlu diuji dengan berbagai cara. Misalnya, salah satu hipotesis mereka adalah bahwa peningkatan kesenjangan TIDAK berhubungan positif dengan peningkatan prestasi. Hipotesis ini diuji dengan merumuskan 3 indikator kesenjangan dan 3 indikator prestasi (yang masing-masing diwakili oleh 10 skor). Mengapa tidak cukup satu indikator saja? Sebagaimana semua variabel dalam riset, "kesenjangan" adalah konstruk teoretis. Barang gaib, nggak kelihatan. Ia bisa mewujud dalam berbagai bentuk (inilah yang kita sebut sebagai indikator). Pengujian dengan 1 indikator mungkin menghasilkan pola yang berbeda dari indikator lain. Jika hasil pengujian dengan berbagai indikator yang berbeda mengarah pada simpulan yang sama, ketika itulah temuannya disebut "robust" alias kokoh, memiliki derajat kepercayaan yang tinggi.
4. TEMUAN SOAL KESENJANGAN MUTU
Analisis yang super rumit dalam artikel ini menghasilkan temuan yang konsisten dan simpel. Peningkatan kesenjangan justru berkorelasi dengan penurunan prestasi. Negara-negara yang prestasinya meningkat justru sekaligus mengalami penurunan kesenjangan. Dengan kata lain, peningkatan prestasi dan pengurangan kesenjangan berjalan beriringan.
Studi kasus pada negara-negara yang paling besar peningkatan prestasinya, seperti Jerman dan Polandia, menunjukkan bahwa perubahan tersebut dicapai dengan cara menaikkan prestasi siswa yang tadinya berprestasi rendah. Bukan dengan cara membantu siswa yang sudah berpotensi menjadi semakin tinggi prestasinya (seperti diprediksi oleh teori yang hendak digugurkan oleh artikel ini). Di sisi lain, penurunan prestasi rata-rata seperti yang terjadi di Swedia dan Islandia terjadi karena turunnya skor siswa yang tadinya memang lemah. Siswa pada persentil atas tetap menunjukkan prestasi yang tinggi.
Implikasi praktis temuan ini sangat jelas. Jika ingin meningkatkan prestasi, fokus pada mereka yang tadinya berprestasi rendah. Program-program seperti sekolah unggulan, perlombaan antar sekolah, dan pembinaan tim-tim elit untuk mengikuti olimpiade internasional tidak akan efektif untuk mengangkat prestasi secara keseluruhan.
5. TEKNIK PENULISAN
Artikel ini tidak hanya kuat secara metodologis. Penulisannya pun ciamik. Mengingat kompleksitas data dan analisis yang digunakan, sebenarnya tak mudah untuk menuliskan hasilnya agar bisa dipahami pembaca. Para penulisnya berhasil menyajikan temuan dengan sederhana. Abstraknya pun sangat singkat, tidak berpanjang-panjang dengan jargon teknis yang takkan dimengerti 99% pembacanya:
"Research suggests that a country does not need inequity to have high performance. However, such research has potentially suffered from confounders present in between-country comparative research (e.g., latent cultural differences). Likewise, relatively little consideration has been given to whether the situation may be different for high- or low-performing students. Using five cycles of the Programme for International Student Assessment (PISA) database, the current research explores within-country trajectories in achievement and inequality measures to test the hypothesis of an excellence/equity tradeoff in academic performance. We found negative relations between performance and inequality that are robust and of statistical and practical significance. Follow-up analysis suggests a focus on low and average performers may be critical to successful policy interventions." (Parker et al., 2018, p.836-7)
Cara penulisan bagian pengantarnya juga bisa menjadi model untuk ditiru:
"Educational policy aims to maximize educational excellence and reduce inequity. The need to balance these demands is an ongoing concern in social mobility (Burger, 2016), educational attainment (Goldthorpe, 2007), and to a lesser degree, concerns about performance in standardized tests (Checchi, 2006). Our paper is primarily concerned with issues relating to the association between national performance in standardized tests (educational excellence) and the degree of variation in performance within a nation (our measure of educational inequity). It is our hypothesis that greater variance in test scores—greater inequality—will be negatively associated with higher average educational achievement—or higher excellence. We seek to directly challenge views that a country’s educational policies must incorporate some inequality to produce higher average test scores. To test this hypothesis, we consider a range of inequality measures. Unlike previous research, we focus on (a) changes that occur within countries over time and (b) where in the academic achievement distribution the changes occur. In the following sections, we first position our research within the broader domain of educational inequity before outlining competing positions on the excellent/equity tradeoff in educational ability. Finally, we consider what empirical research currently suggests about this debate and the limitations with the existing evidence base that we seek to overcome." (Parker et al., 2018, p.837)
Untuk mengapresiasi cara penulisan paragraf pengantar ini, silakan bandingkan dengan bagian pengantar kebanyakan artikel di jurnal dan tugas akhir yang pernah anda baca.
Ini tautan menuju artikelnya: https://doi.org/10.3102/
Ingin baca tapi tidak punya akses? Be creative :D